

多主机多gpu
服务器知识
2025-03-25 12:20
188
多主机多GPU环境下的深度学习训练与优化
一、 引言
随着深度学习技术的发展和应用领域的不断拓宽,大数据、高并发的环境下对计算资源的需求也日益增长。在深度学习训练过程中,如何利用多主机多GPU环境来提升训练效率与性能是一个热门的话题。本文主要讨论多主机多GPU环境下的深度学习训练及优化方法。

二、 多主机多GPU环境下的深度学习训练
在多主机多GPU环境下进行深度学习训练,主要涉及如何有效地管理和分配计算资源。具体方法包括以下几点:
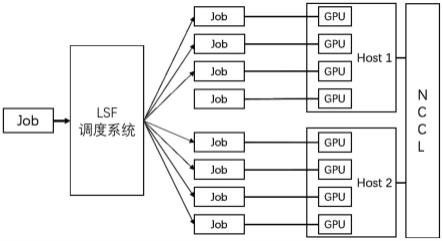
1. 模型并行化
模型并行化是将深度学习模型的不同部分分配到不同的计算节点上进行处理。例如,可以将模型的某些层分配到不同的GPU上,通过并行计算提高训练速度。
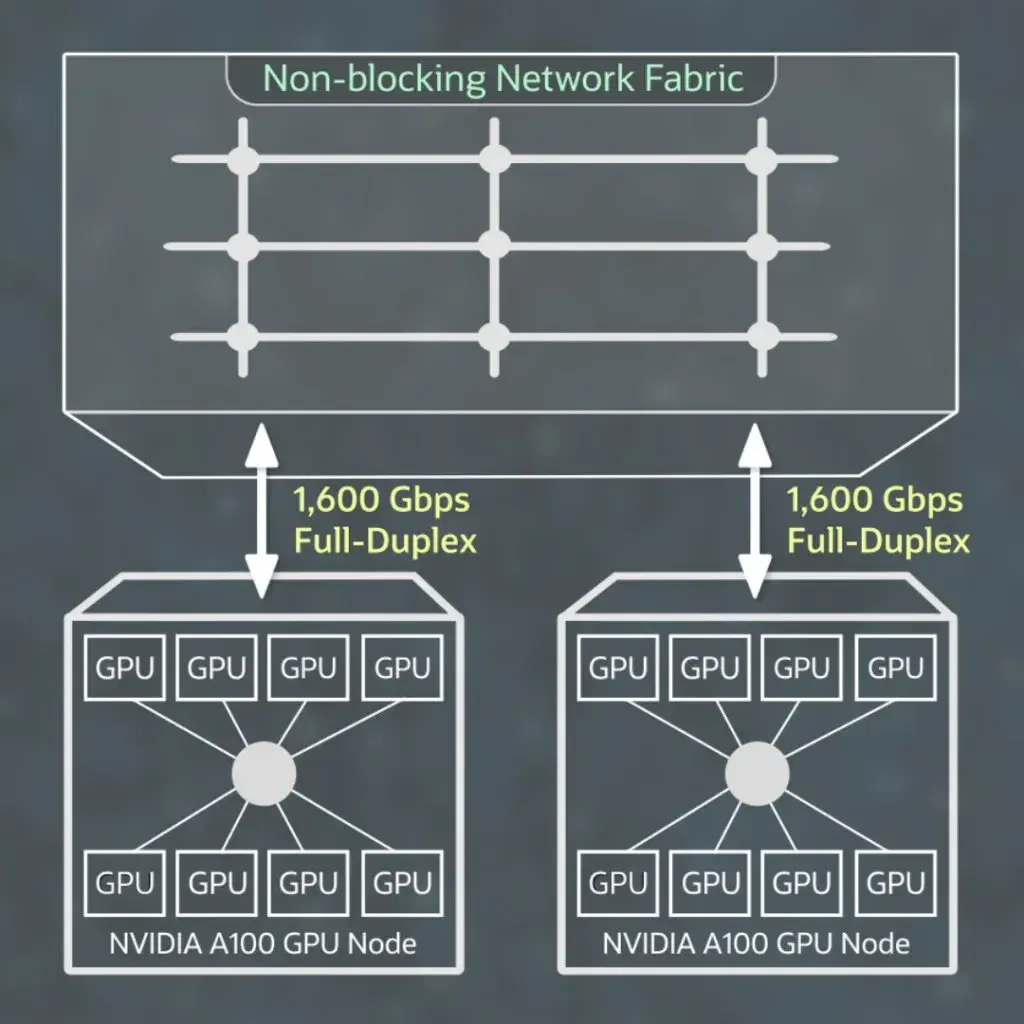
2. 数据并行化
数据并行化是将数据集分割成多个部分,每个部分在不同的计算节点上进行训练。这种方法可以有效地利用多主机多GPU环境的并行计算能力。
3. 使用分布式框架
使用分布式训练框架如TensorFlow、PyTorch的分布式版本等,可以方便地利用多主机多GPU环境进行深度学习训练。这些框架可以自动管理和分配计算资源,提高训练效率。
三、 多主机多GPU环境下的优化方法
在多主机多GPU环境下进行深度学习训练时,还需要考虑如何优化性能。主要优化方法包括以下几点:
1. 优化网络传输
在多主机环境下,数据在各节点间的传输效率直接影响训练速度。因此,需要优化网络传输,减少数据传输延迟。
2. GPU资源优化管理
合理分配和管理GPU资源,避免资源浪费和冲突,是提高训练效率的关键。可以使用工具如NVIDIA DCGM进行GPU资源管理。
3. 算法优化
针对具体的深度学习算法进行优化,如使用更有效的优化器、调整超参数等,可以提高训练速度和模型性能。
四、 总结与前景展望
本文介绍了多主机多GPU环境下的深度学习训练方法和优化技巧。随着技术的不断发展,未来可能会有更多高效的方法和技术出现,以提高多主机多GPU环境下的深度学习训练效率和性能。我们期待更多的研究和探索。
Label:
- 关键词:多主机多GPU环境
- 深度学习训练
- 模型并行化
- 数据并行化
- 分布式框架
- 网络传输优化
- GPU资源优化管理
- 算法优化